Pika主从SyncWin崩溃追踪(Issue 2665,2659,2655)
说明:
本文共有3个Pika主从问题的追踪梳理过程。
本文之前主要用于自己记录追踪进度,以及向组里同学说清楚追踪过程以及修复方案。
但恰好Pika是开源项目,遂在隐去日志里的内网IP,以及征得老板同意后将之前Debug的部分梳理过程贴了上来。
对应的Issue:
https://github.com/OpenAtomFoundation/pika/issues/2665 (问题4: Binlog Ack Start 大于Binlog Ack End)
https://github.com/OpenAtomFoundation/pika/issues/2659 (问题5: 二次TrySyn引起的问题 )
https://github.com/OpenAtomFoundation/pika/issues/2655 (问题6 超时重连后从可能提供错误的续传起始位置)
对应的PR/修复代码:
https://github.com/OpenAtomFoundation/pika/pull/2638
https://github.com/OpenAtomFoundation/pika/pull/2666
以下是之前的部分追踪梳理:
问题4(Issue 2665)
主从如果因为某些原因超时断开连接后(如网络波动),再次重新建立增量连接,可能出现主从发送窗口崩溃。具体地:Slave回复的某条BilogACKOffset中,EndOffset竟然小于StartOffset,十分离谱。
不过此问题只发生在多DB情况下,而线上都是单DB部署,所以线上没有出现过这个问题。
20240429更新:问题4能稳定复现,先追这个
问题4追踪:
1 Master发生Corruption的地方:可以发现,Slave给出的AckEnd小于AckStart,而AckEnd是从Slave调用GetProducerStatus取得,取的是Slave在那一时刻最新的BinlogOffset,反映的是SlaveBinlog的落盘情况,如果没有出错,该值就应当刚好等于Master这一次发过来的这一个BinlogChip的最后一个Binlog的Offset,这里AckEnd更小,说明Slave实际落盘Binlog的进度落后于实际预期,是不正确的。

去看Slave端,再发出这条BinlogAckOffset的时候,end就小于start,所以也不是master端接受到BinlogAck后解析错误,slave发过来就是这样,应该就是Slave端的实际落盘Binlog进度落后于正确预期
2 回去看Master发送的BinlogChip,上面报错的这条BinlogChip,由Master发出的时候,看起来没有问题

3 但是再往前看Master发出的一条条BinlogChip,发现Master在从binlog file 49到binlog file 50时,缺了一段没发

这个地方Master少发了一段Binlog, 从file:49, offset:99863248(95.23MB)到file:50, offset:13603632(12.97MB)这一段内容被跳过了,没有发出相应BinlogChip,就像是发送窗口里少了这一截一样。这一段的大小大概在:100-95.23+12.97=17.72MB
4 再回到Corruption的地方去计算:本来这条以start为(50,13603632)开始的binlogChip,最后一条binlog为(50,14626232),也就是Slave预期的落盘点是fnum:50,offst:14626232(13.94MB)。而现在slave的实际落盘点是:fnum:49,offst: 100896176(96.22MB), 该位置和预期的正确落盘点缺口大小大概为:100-96.22+13.94=17.72MB,恰好等于Master发送BinlogChip时漏掉的那一块。
Slave落后的大小,刚好是Master发送的那个缺口大小,基本可以确定这个Corruption的原因是Master端少发了一截binlog引起的(而不是binlog都到了slave端,slave自己漏消费导致)。
补充1 正常情况下Binlog文件切换也不会有这么大的缺口:

补充2 Master漏发Binlog并不只发生在跨越文件时,这里另外一次复现,就没有跨越文件,但是漏发了5.92MB的Binlog

补充3 经过尝试,哪怕先空DB建立建立主从关系,后面纯粹靠增量复制同步,也会复现该问题
Master为啥会发生Binlog发送的遗漏 ?
1 在SyncWin和WriteQueue附近增加日志,复现场景,初步观察,从文件读取Binlog,加入SyncWin和WriteQueue这里看起来是没有缺口的
2 在WriteQueue入队部分监控前后两个入队task的距离(大于512KB就进我的断点),但是这个断点分支从没进去过,也就是在入队的部分,task(Binlog)之间也没有缺口
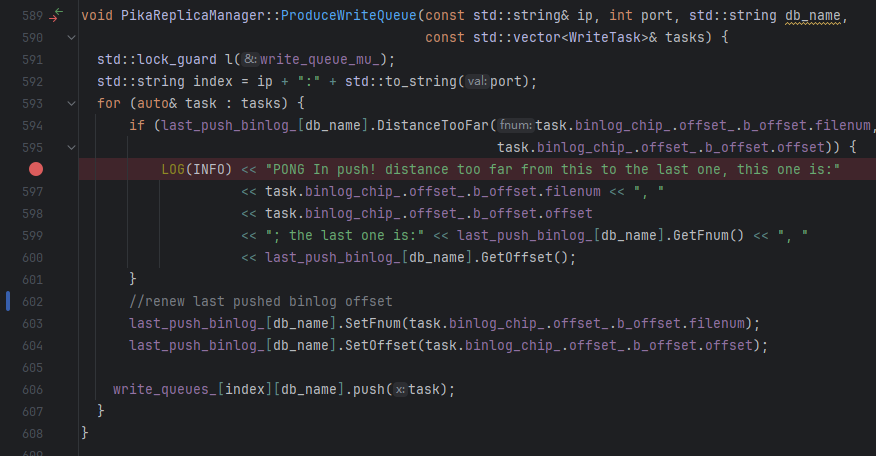
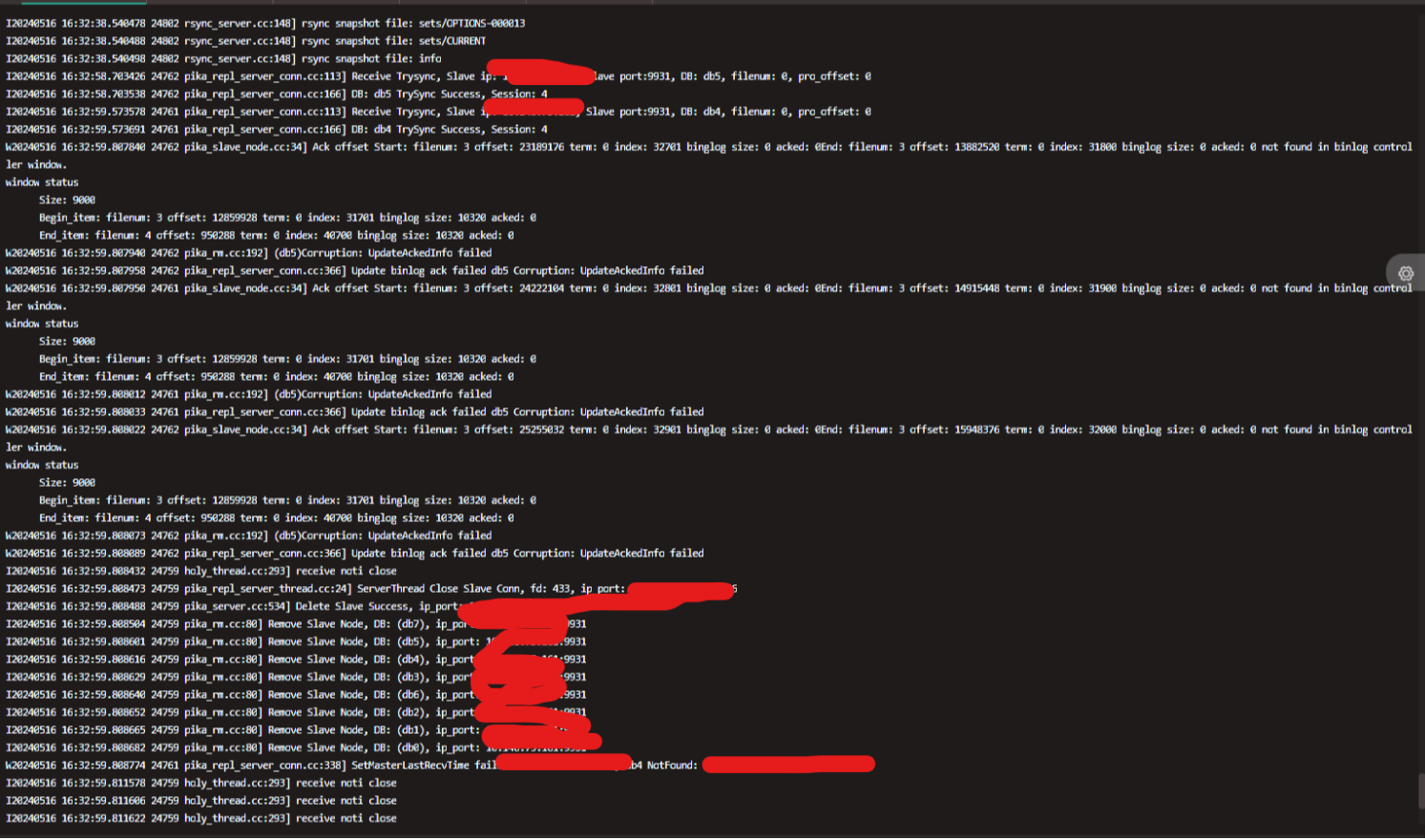
3 在writeQueue出队部分监控前后两个出队的task(Binlog)之间的距离,每次复现问题GDB都会捕捉到这个分支(如果前后两条binlog距离太远)上的断点,所以在writeQueue出队部分莫名出现了缺口

也就是说,问题出在WriteQueue上,这些Binlog放入WriteQueue的时候可以确定是没有缺口的,连续的,但是从WriteQueue中Pop出队的时候少了一大片。结论是:已经加入到了WriteQueue中的Binlog消失了一部分!
4 在WriteQueue所有涉及erase的地方都额外添加日志,重跑复现问题,这次似乎有所收获:
在中间(8468行)发生了一次WriteQueue的Erase,并且是单个Slave对应的所有的WriteQueue(每个DB一个WriteQueue)都被清空了,并且Master似乎并没有意识到Erase的发生,依旧在继续往后读取Binlog,填充SyncWin和WriteQueue,于是发生Erase行为时,处于WriteQueue中被清除的Binlog就成了前面发现的Binlog缺口。
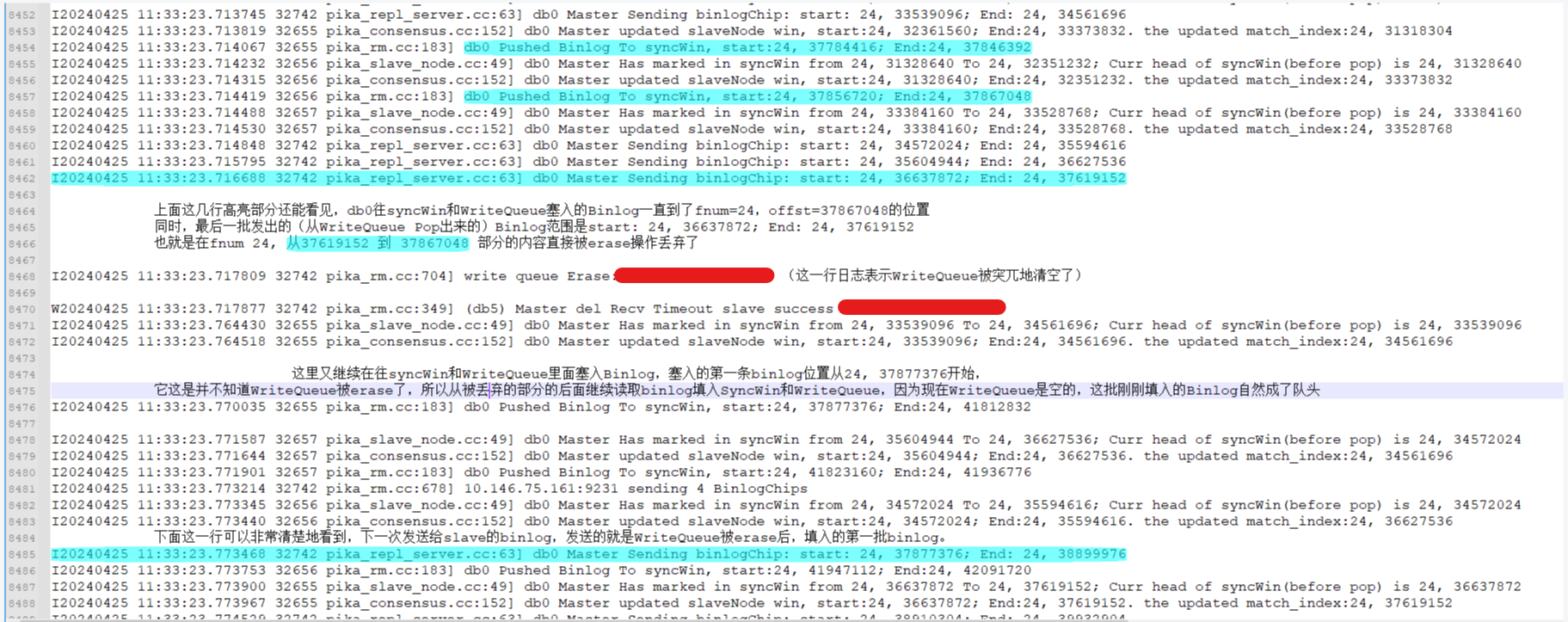
5 几乎可以断定,4中提到的WriteQueue的Erase不是预期行为,应该是个Bug。
6 根据日志产生位置,可以定位到引起WriteQueue清空的地方在Auxiliary Thread针对MasterDB检查超时时间的部分,
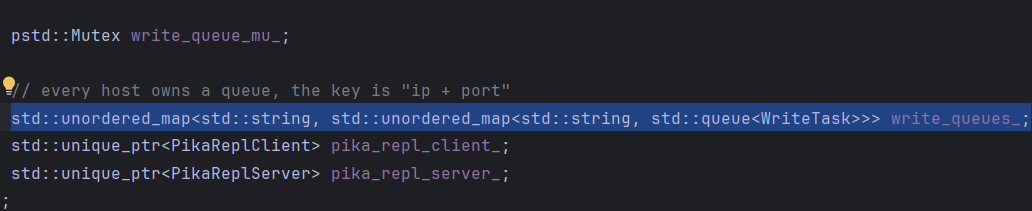
背景1 首先多DB情况下就有多个SyncMasterDB,假设目前只有一个Slave节点连接上来,其实每个SyncMasterDB内部就只有一个SlaveNode,逻辑上连接到了Slave机器上对应的SyncSlaveDB,SyncMasterDB通过SlaveNode,同从节点上某个SyncSlaveDB建立的逻辑连接,是DB到DB的连接。假如一个场景中,主从都有N个DB,1主1从。则主节点有N个SyncMasterDB,每个SyncMasterDB内部都有1个SlaveNode,也就是在主节点中其实有N个SlaveNode,而每个SlaveNode都有自己对应的WriteQueue,共N个WriteQueue
6.1 问题4的直接原因找到了:一旦有某个SlaveNode(只是对应一个DB而已)超时,竟然会清空该对应该从节点的多个SlaveNode的WriteQueue,”某个DB超时,我就判定整个节点的所有DB不可达“这种逻辑不是说一定就错,但这里很明显的逻辑问题就是:347行只移除了1个SlaveNode,但是却清空了N个WriteQueue
补充:在另外一个函数SyncMasterDB::ActivateSlaveBinlogSync中有相同的情况,该函数的职责是某个DB发送TrySync建立增量关系后需要初始化SyncWin和WriteQueue,他会对WriteQueue进行清空重置,同理,他也是会Erase无关的WriteQueue
6.2 现在还要回答两个问题:
1 这种超时怎么来的,是否又是一个BUG
这里回到了问题3,请见问题3的追踪流程
2 正确的行为应该是怎么样的: 当真的有不可避免的单DB超时时,是应当移除单个SlaveNode,并且清空其对应的WriteQueue,还是直接将超时DB的兄弟们(关联到同一个从节点的其他SlaveNode)全部移除,并且移除他们对应的这多个WriteQueue
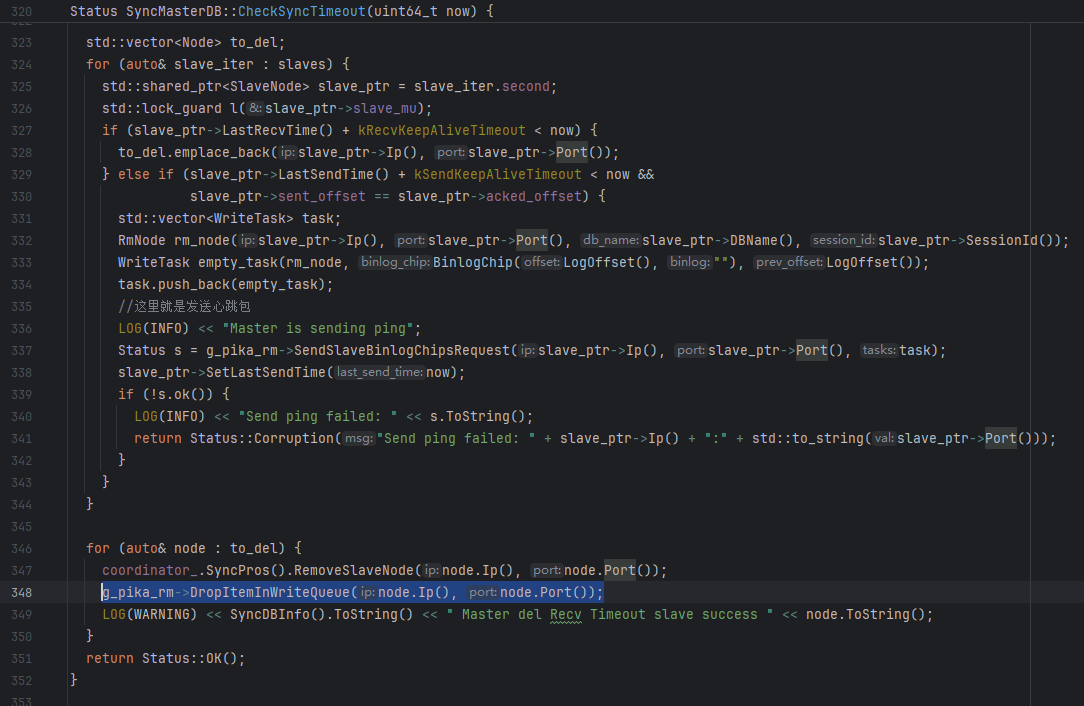
可以看到,用Ip&port移除slaveNode,是只移除了一个。
但是却清空了多个WriteQueue

6.3 到这里也能解释为什么这个问题只在多DB场景下有,在单DB场景下没有:
场景1 单DB,一主一从:主节点内存中维护1个SyncMasterDB,其内部有1个SlaveNode,对应着一个WriteQueue
这种情况下全局总共都只有1个WriteQueue,不会有失误清空无关WriteQueue的情况
场景2 单DB, 一主多从,清空WriteQueue时是用slave的IP&Port来定位WriteQueue的,因为是单DB,所以对应一个IP&PORT的只有1个slaveNode,也就是只有1个WriteQueue,所以不会擦除其他从节点的WriteQueue。 (相应地,多DB情况下,用一个IP&Port能取到的是多个WriteQueue,所以会有无关擦除)
6.4 针对这个问题的解决方案:
某个DB发生超时时,删除其对应的SlaveNode,并且只清空和这个SlaveNode对应的WriteQueue,无关的WriteQueue不碰!
修复结果:问题4解决了,但是发现在“超时断联,重连继续增量同步”这一个场景下,还有别的问题,而且问题很多(引出了问题5)
问题 5(Issue 2655) 针对问题4进行修复以后,发现“超时断开后重连进行增量同步”场景中依旧能测出其他窗口问题, 同时DBA那边上次给的一个故障实例,从报错来看也是几乎一样,后经确认是同一个问题,只是线上实例引发主从断联的原因是从节点RocksDB write stall,导致binlog worker也被夯住,进而导致主从断开。
1 现象:返回的一条BinlogACK跨度特别大,从Ack Start到AckEnd的90%都已经不在SyncWin中了,所以报SyncWin Corruption

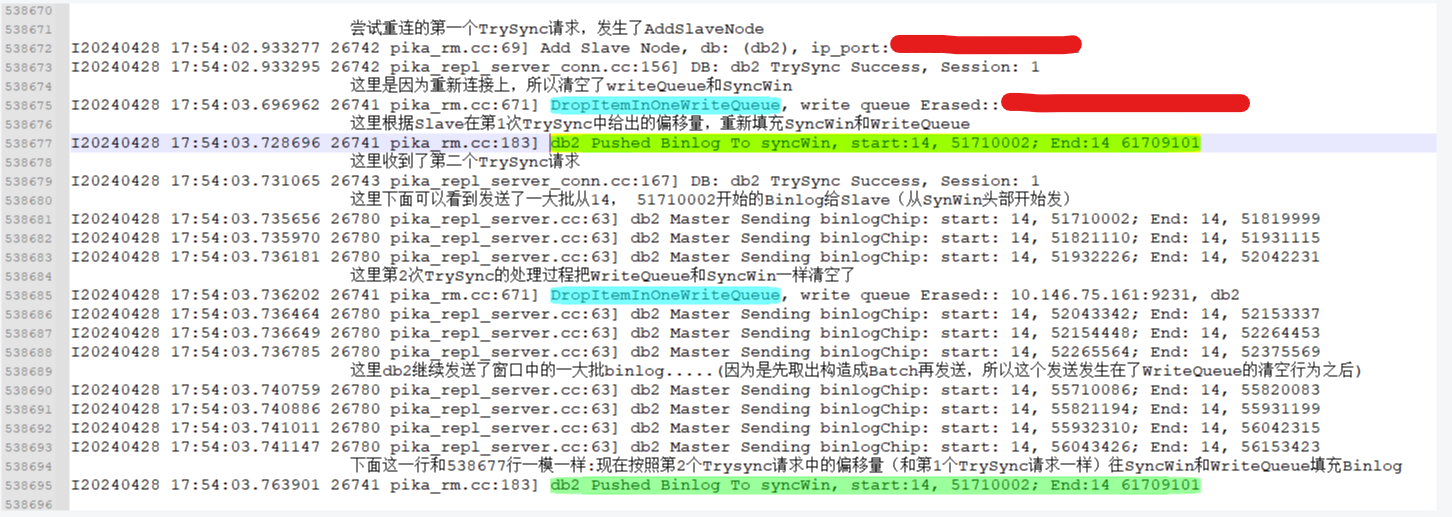
2 排查到的直接原因:Slave在超时重连时,在短时间内连续发出了2次一模一样的TrySync请求(参数中携带的BinlogOfft都一样),Master端会对这2条TrySync请求做同样的处理(每次都会清空WriteQueue和SyncWin,然后从TrySync请求中携带的Binlog偏移量位置开始发送Binlog)
于是会出现下面这种情况:
假设Slave的起始续传位置是1,在尝试重连时Slave连着发出了2条TrySync,收到第1条TrySync后,Master会清空WriteQueue和SyncWin,将Binlog 1到100填充进SyncWin和WriteQueue(假设SyncWin容量为100),而后立刻分批发送了SynWin中Binlog 1-50, 此时Master收到第2条TrySync请求,于是又会重新清空WriteQueue和SyncWin,再次填充 1-100,然后再重新分批发送Binlog 1-50,这样Binlog 1-50就被发送并且消费了2次(下面会说为什么第一批Binlog1-50会被消费),而且Slave在消费第一批Binlog 1-50时,返回的ACK会将SyncWin中对应的Binlog Item出队,所以从节点消费的第二批Binlog 1-50,所产生的ACK返回给Master时,Master就会发现SyncWin中找不到对应Item,进而报出上图中的窗口错误。
下面的日志就是复现的一个实例:
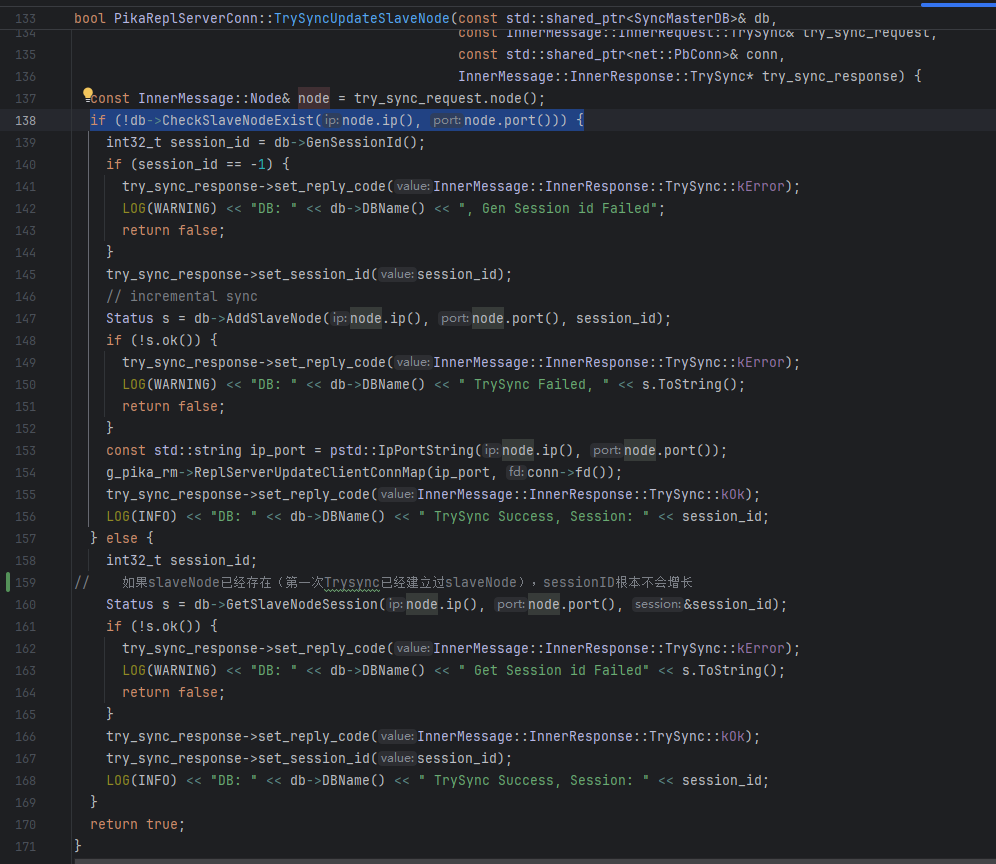
3 要搞清楚的一个问题:即使Master发送了2次Binlog1-50, 为什么Slave会去消费第一批Binlog 1-50, Slave重新恢复Connected状态时,SessionID应该已经是第2次TrySync Resp带回来的SessionID了,为什么还会消费第一批Binlog 1-50(由第1次TrySync发出的):
因为第二次TrySync时,Master根本不会增长SessionID,具体逻辑如下:
如果SlaveNode已经存在,Master不会对SessionID做增长,而是直接取了SessionID就返回。所以第1次TrySync和第2次TrySync建立的主从SessionID都一样。
可以再看这个下面这个图:两次TrySync带回了相同的SessionID, 其实第1次TrySync期间发出的Binlog 1-50,是在第二次TrySync建联以后被slave消费的
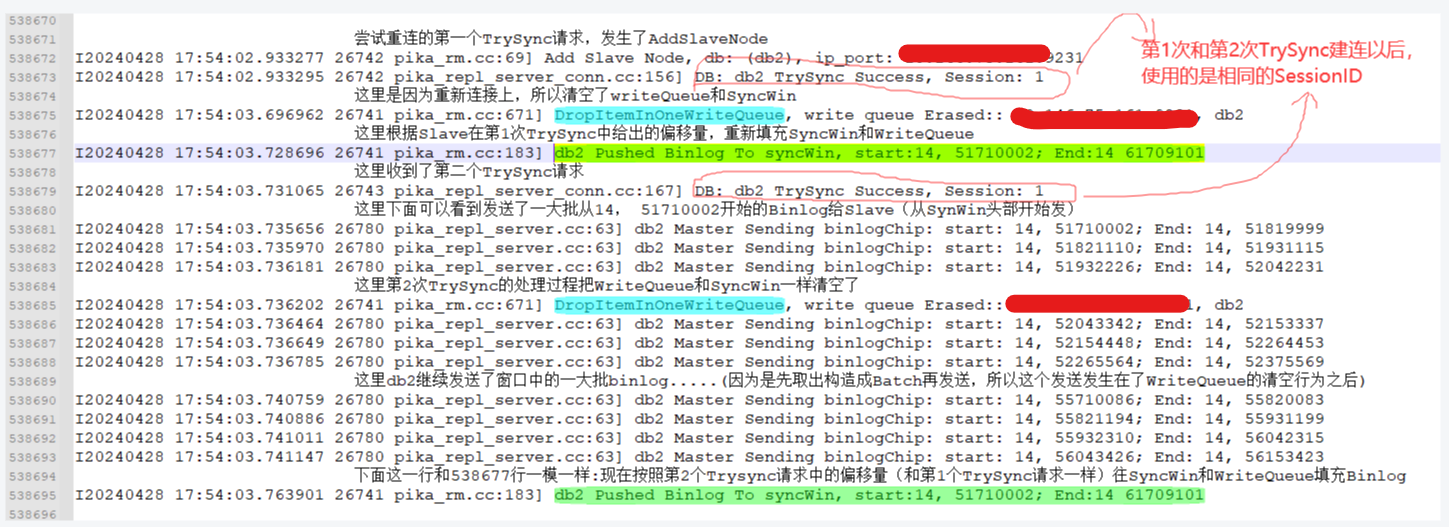
上图有一个地方需要修正一下说法: Master并不是直接使用TrySync携带的offset去填充窗口的。 TrySync请求携带的offset主要作用是给Master判断是否能做增量同步,真正决定Master初始化发送窗口起始位置(续传Binlog的起始位置)的,是slave在收到TrySync的resp后发出的一条特殊BinlogACK,该ACK的start等于end,且该值就是slave的最新落盘点,这个值大概率等于TrySync携带的Slaveoffset,也可能比TrySync的offset大一点(如果发送TrySync的时候还有一个来自上一次主从期间的写Binlog任务正在处理的话)。
4 下一步是排查:为什么Slave会连着发出两次TrySync请求:
先说结论:Slave端消费Binlog的Worker线程的任务队列在发出第一次TrySync时依旧还有上一次主从连接期间积压的写Binlog任务(Slave端超时断联,转入TryConnect状态时,会去一条一条丢弃此时WorkerThread中积压的写Binlog任务,这里的问题是丢得太慢了或者说下一次TrySync发的太快了),当Slave收到第一条TrySync请求的响应,会进入Connected状态,于是会开始消费之前积压的,来自前一次主从连接的写Binlog任务,而这些BInlog的SeesionID对不上,就会触发错误处理分支,将Slave转到TrySync状态,所以slave紧接着发出了第二条TrySync请求。
梳理过程:
4.1 首先,从日志可以看到,第一次TrySync请求是成功了的(Master收到了TrySync请求,返回了reply_code为ok的resp,且Slave收到了这个resp,进入了Connected状态,开始增量同步)
4.2 在多次的复现中,都能观察到在 收到第1次TrySync的resp后,发出第2次TrySync请求前,会有日志:Check SessionId Mismatch .....

这部分日志对应的代码来自:PikaReplBgWorker::HandleBGWorkerWriteBinlog,具体地逻辑是Slave消费每条Binlog都会检查SessionID是否相同,而这里检查失败了,所以转入了TryConnect状态
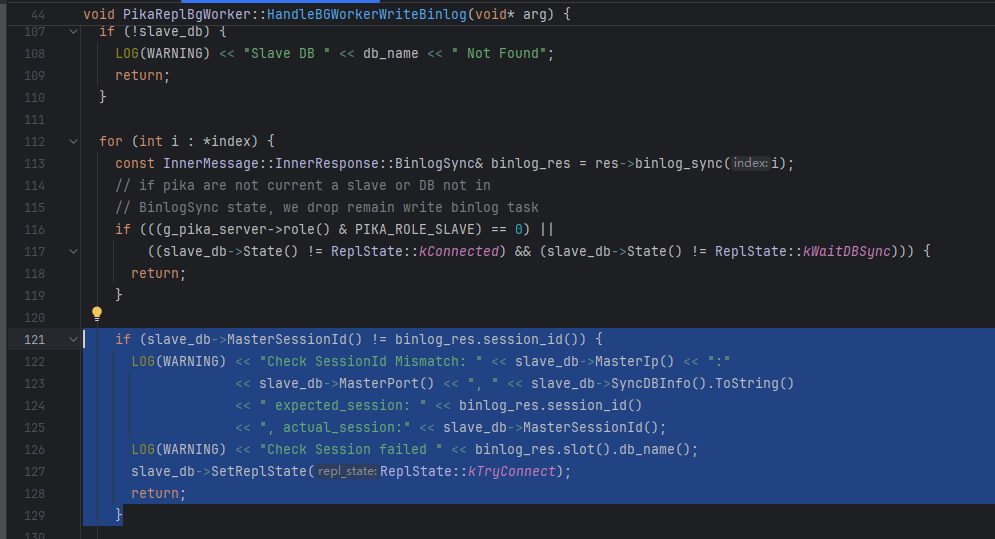
刚好在这一段逻辑往上刚好也能看到Slave端丢弃过期Binlog任务的逻辑(这里说的过期,指的是那些主从断联时,还处于worker线程任务队列,未来的及消费的写Binlog的任务)。可以看到Slave端清空这些任务的方式不是主动的对任务队列进行erase,而是在处理这些任务的时候,判断当前是否还处于Connected状态,如果已经不处于该状态,就直接return,丢弃这条任务(所有过期任务都会走这么一遭,所以完全清空队列中的过期任务,可能稍微需要一点耗时)
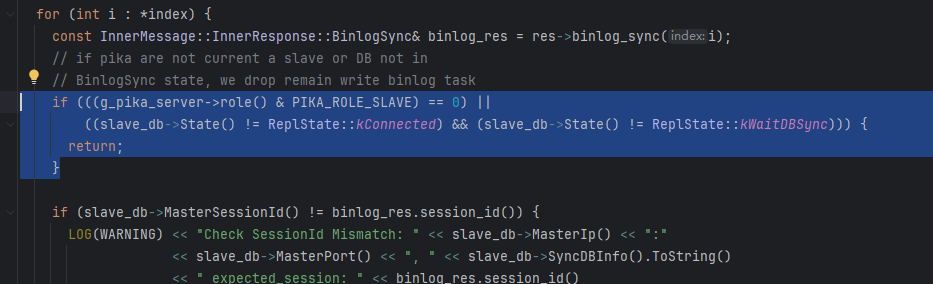
这次复现在slaveWorker的任务队列附近也增加了日志:
1 在发出TrySync前日志输出各个SlaveWorker任务队列的剩余任务量(出问题的是db6,其对应的slaveWorker是worker 4):
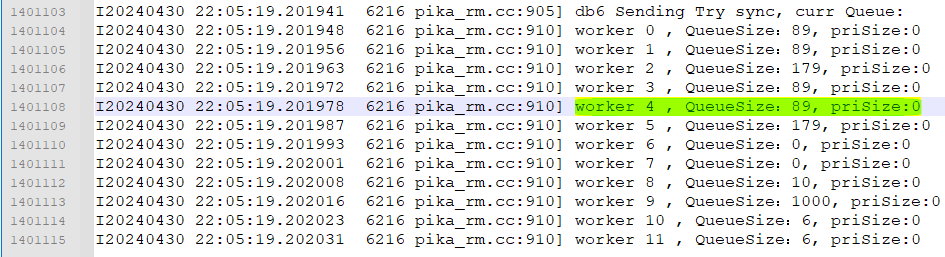
可以看到,在发送TrySync请求时,db6所对应的worker4中还积压这89个过期任务没来的及丢弃。
2 在Slave端进行任务丢弃时输出日志: 可以发现db6在发出TrySync时还有89个过期任务没有来得及丢弃,于是他继续丢弃过期任务,但是只丢弃了3个任务(还有86个过期任务本来应该丢弃),就已经收到了trySync的resp,转入Connected状态,继续消费任务队列里的写Binlog任务,所以消费得到的第一个任务就是过期的,于是CheckSessionID failed,会重新转入TryConnect状态。
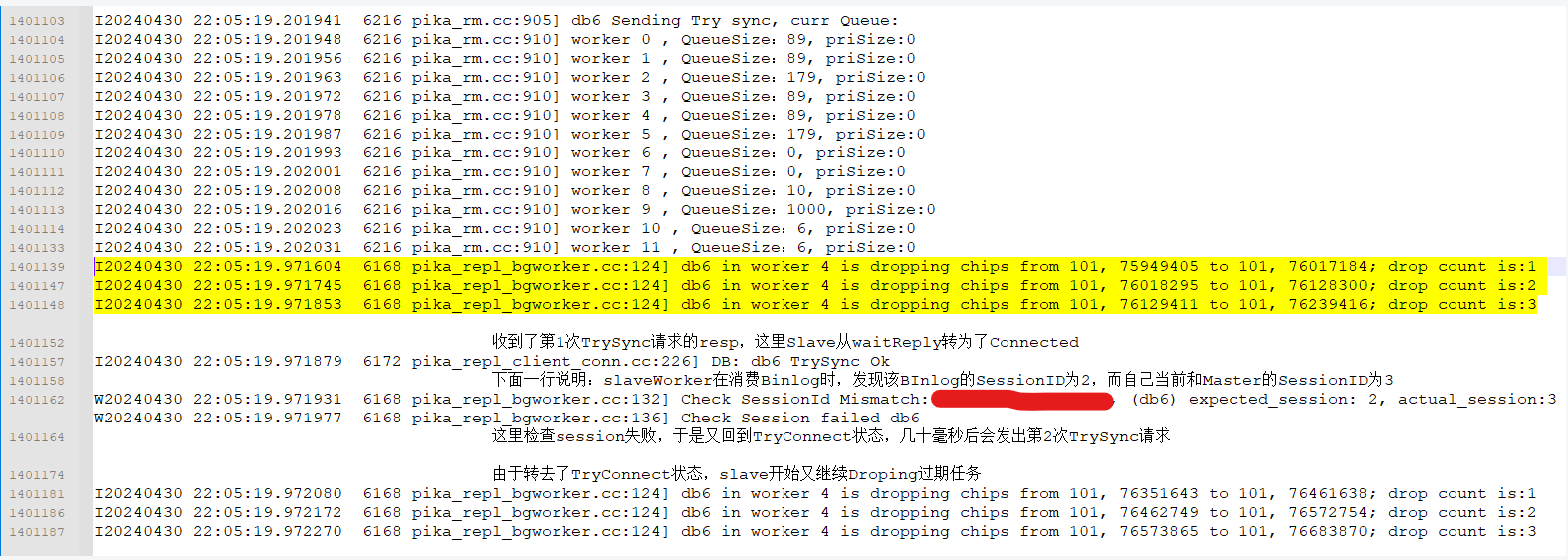
我认为上面的梳理过程基本可以支撑最开始的结论:由于slave消费了过期的binlog任务,导致CheckSeesionID失败,转入了TryConnect,进而再次发送了TrySync,这个二次发送的TrySync又恰好因为Master端的SlaveNode还存在,所以不会带来SessionID的增长,所以导致一批被重发过的Binlog也能进行消费,进而导致同步窗口Corruption
5 可选的修复方法
5.1 修复方案1:在SlaveDB发出TrySync请求之前,先检查该DB对应的BinlogWorker是否还有积压的任务,即该worker的QueueSize是否为0,如果为0就发TrySync,如果不为0就跳过每次状态检查,等一会后(至多100ms)后再次检查是否能发TrySync(BinlogWorker处于TryConnect状态时也会逐条对Binlog任务进行丢弃)。这样就确保了Slave发送TrySync时已经没有了积压的过期Binlog任务,自然不会后面在进入Connected状态后消费到过期的Binlog任务。
5.1.1 该方法需要考虑的case 1:假如有多个DB共用一个BinlogWorker,如DB0,1共用worker A,当DB0处于TryConnect时,可能会因为DB1往worker A里提交了Binlog任务而导致迟迟看不到worker A的QueueSize为0,进而导致TrySync迟迟无法发出。如果在重构Slave worker model部分时强制让每个DB都独享一个worker可以解决这个问题,但会降低用户配置的灵活度。
5.1.2 该方法需要考虑的case 2:哪怕等到QueueSize为0了才发TrySync,当发出TrySync那一刻,如果该worker正在处理一条属于上一个Session期间的BInlog任务怎么办
5.2 修复方案2:在Slave端修改消费到过期Binlog时的逻辑,原本的逻辑是:丢弃当前Binlog并转入TryConnect状态。 修改为:只丢弃当前过期的这个Binlog任务,不修改状态。这样就不会触发第2次TrySync请求。
5.2.1 该方法需要考虑的case:似乎有很多case需要考虑,如果要采用该方法,务必要搞清楚这里原代码要转入TryConnect的目的是什么,拿掉这个操作到底安不安全
5.3 (最终采用的)修复方案3:让SlaveDB处理TrySync的Resp时,使用该DB对应的那个BinlogWorker来进行;另外一种表述方式是:让Slave对TrySync Resp的处理(会将SlaveDB转入Connected状态)排在过期Binlog任务的后面,这样就能确保在转入Connected状态前所有过期Binlog任务都会被丢弃。
背景: 原代码使用了哪些线程处理了TrySync的Resp? 轮流使用所有workers来处理这些response(BinlogWorkers和WriteDBWorkers都在轮询范围内),所以原代码中,Slave端对TrySync Response的处理是异步的(相较于消费Binlog是异步),也就导致了:”过期任务还没丢完,SlaveDB就进入了Connected状态“
5.3.1 Edge Case 1: Slave在增量同步阶段,发生超时转为TryConnect状态,在发出TrySync请求时,如果相应的BinlogWorker正好还在执行一个上次连接期间的Binlog任务(将该Binlog任务定义为任务A)
那么,因为任务A的存在,Slave是否可能会发送了不正确的续传起始Offset给Master ? 换句话说:虽然最终任务A会落盘,但是Slave 告知了Master从任务A之前的位置发送Binlog,导致Master会将任务A对应的Binlog再发一次,且Slave会消费两次任务A所对应的Binlog ?
背景补充和定义:TrySync请求携带的offset(定义为offset A)主要作用是给Master判断是否能做增量同步,真正决定Master初始化发送窗口起始位置(续传Binlog的起始位置)的,是slave在收到TrySync的Resp后发出的一条特殊BinlogACK (is_first_send=true),该ACK的offst start等于end(定义为Offset B),且该Offset B就是slave在发出这条特殊Ack时的最新落盘点。在大多数情况下,其实Offset B应该会和Offset A相同,但是在Edge Case 1中,由于发出TrySync时任务A正在执行且最终会执行完毕,Offset B的正确预期应当是 Offset A + BinlogSizeOf(任务A), 或者说Binlog的起始续传位置应该就在任务A对应的Binlogs的后面。
问题6 是一个独立的BUG(Issue 2659): 在原版代码中,Offset B可能不会等于正确预期:假如BinlogWork执行任务A执行了比较久,而在任务A的执行期间Slave完成了:TrySync Req发送 ->TrySync Resp处理->在TrySync Resp的处理函数末尾会获取Slave最新的Binlog落盘点(Offset B),发出特殊BinlogAck(is_first_send=true)来告知Master从哪里开始重发Binlog。 如果在获取Offset B的时候,任务A还没落盘,或者落盘了但是还没有将最新的offset更新到version_对象中(Offset B就是从version_对象中取),就会导致获取的OffsetB就等于Offset A(但正确的应该Offset B应该是 Offset A + Offset A + BinlogSizeOf(任务A))。上面这个BUG的触发条件相对比较苛刻:这个执行了很久的任务A,必须是上一个Session中的最后一个任务,否则就会因为有积压的过期Binlog触发二次TrySync的问题。
后果:Master会把任务A内部的BInlog再发一次,Slave等于消费了2批同样的Binlog,一次是在上一次Session的末尾,一次是在新Session的第一个Binlog任务中。可能会导致主从数据不一致,而且Slave可能完全不会报错(在同步没有滞后/完全同步的情况下,Slave的Binlog文件会比Master的对应BInlog文件长一点,在Slave切走这个Binlog文件之前如果发生了断点重连,可能会报错 binlog offset is not a start point of master, 但是如果slave在处于该Binlog文件期间完全没有断开过,后面切换到了新BInlog文件,就完全不会报错了, 但数据可能是不一致的,因为pika binlog不幂等)
落实方案3以后的情况:
1 可以解决"消费到过期Binlog而发出二次TrySync进而引发窗口崩溃"的问题:因为在转入Connected状态之前(处于TryConnect/WaitReply时),Worker对于BInlog任务一律都是丢弃,而TrySync Resp的处理函数就负责将Slave从WaitResply转到Connected,如果将TrySycn Resp的处理排到了同一个BinlogWorker上,过期任务一定都排在TrySync Resp的处理任务前面,也就是一定是先丢弃了所有过期Binlog任务,才会转入Connected状态,于是二次TrySync的这个问题就解决了
2 针对上面提到的新BUG,在方案3中也不会出现:因为告知Master重传起始位置的特殊ACK是在TrySync Resp的处理逻辑尾部发出的(在TrySync Resp的处理逻辑尾部去获取了Slave最新的BinlogOffset),在落实了方案3以后,这条特殊ACK在获取SlaveOffset的时候,任务A一定是落盘了的,所以拿到的Offset B就会是 Offset A + BinlogSizeOf(任务A)
PS: 拉会讨论后,鑫姐(白鑫)提出的需要考虑的case:
Case 1 前面消费binlog的线程阻塞的时间比较长 会不会导致长时间不能发trysync
陈俊华:TrySync请求本身是由Auxiliary线程异步发出(发现已经超过20s没有收到任何Master的消息了),修补方案3也不需要在发TrySync前等待QueueSize清空,所以TrySync的发出不会被延迟。但确实,”Binlog线程被单个任务阻塞时间非常长“这个case确实需要额外考虑,请继续往下看,我会梳理另外一个case:假如单个Binlog任务阻塞了70s,期间slave发出了3次TrySync,主从是否还能正常工作。
Case 2 丢弃的速率如果比较慢,是不是也会影响发trysync。快速建立主从关系,还是很重要的。业务在从库上读。
2.1 陈俊华:BinlogWorker丢弃任务的速率会不会太慢:不会。
丢弃速率大概是14个/ms。丢弃速率怎么推测的:在复现"二次TrySync问题"的某个Case中,Slave检查SessionID失败,会转入TryConnect状态然后return,于是SlaveWorker又开始继续丢弃Queue中的未丢完的Binlog任务(前面消费到了第一个过期的binlog任务,但是在这个任务后面还有其他过期的任务,现在进入了TryConnect/WaitReply就会继续丢弃), 每丢弃一个任务都进行一次日志输出,得到:


可以看到,丢弃86个过期任务只花了大概6ms,BinlogWorker的任务队列最大容量是是1000,即使极端情况下队列里都是过期任务,丢弃所有任务大概只需要70ms,即使考虑线程调度和其他因素,这个开销让他大十倍二十倍,最多也就是几秒钟就能丢干净。
当然,看着也有点奇怪:既然丢任务这么快,那为啥之前过期任务就没有丢干净,导致了二次TrySync呢: 因为那个正在阻塞的任务占有了BinlogWorker,BinlogWorker还忙着,自然不会去pop下一个任务出队,也就不会有丢弃的行为,直到那个阻塞任务完毕了,BinlogWorker才会继续Pop下个任务,而此时可能已经重新建立过一次连接了,消费到的下一个任务自然就是过期任务。(发出TrySync的是Auxiliary Thread, 处理TrySync Resp的大概率是其他worker,都是异步完成的,所以很有可能BinlogWorker这里还堵着,主从却已经完成过一次超时断开和重连了)
2.2 陈俊华:鑫姐提到的快速建立主从关系确实很重要(太久无法回到Connected状态,运维也会告警),但是从2.1的分析也能看到,在落实方案3以后如果出现超时后主从关系花了很久才建立成功(由于TrySync的resp延迟执行了,Slave可能会处在WaitReply状态很久),得归咎于阻塞的那个任务本身堵了太久(丢弃过期任务没啥时间开销)
但是要说的是,即使真的落实方案3以后,在某些极端情况下(从阻塞极其严重),也不能说这个情况就是方案3引起的,因为按照以前resp异步处理的逻辑,resp的处理确实很快,从主从状态指标来看,主从也是正常的
正不正常,从两方面来看:
1 究竟能不能对外正常提供服务:主从其实都可用
2 对运维暴露的监控指标会怎么样:确实可能在运维那边看到master_status_link为down会比较久
2.1 要么可以告诉运维,mater_status_link处于down,且slave状态为waitReply时,可以多等等再告警
2.2 要么找一找PIka为啥会超时,有没有哪里不合理,如果都合理(阻塞是必须发生的),是否考虑增加一点手段让主从维持一点通信,以避免超时
1 这里提到的快速建立主从关系,其目的是否是”高可用“ ? 如果是,那假如按照这个方案修补,阻塞了TrySync Resp的处理后,是否能维持主从可用 ?
1.1 答案是可以,不论是主还是从(处于WaitReply状态),在被延迟转入Connected状态期间,都依旧能向外提供服务。
1.2 甚至从实质上(撇开监控、状态指标)来看,主从消费关系都没断。只是因为从节点消费某一批Binlog时间过长,形式上的主从关系断了,主要的副作用就是会因为太久没有回到Connected状态而导致运维告警。
2 怎么去解决:核心就是能让状态快速回到Connected,或者干脆不断连
可以遇见的:Binlog都是消费一整批才返回ACK,一批BInlog内部的Binlog量越多,期内包含的慢命令越多,执行时间越长;
2.1 从形式上维持住主从连接:提供动态调整主从超时时间的支持,如果主那边的慢命令负载越多,这个超时时间可以越久
2.2 让一整批Binlog分批回复:比如每消费完一条BInlog就获取一下时间戳,看本批Binlog消费时间是否有达到一个给定时间(比如10s),如果有,就先将已经消费了那些BInlog的Ack先返回(即单个Binlog消费任务返回多次Ack),这样除非单个写任务超过了20s,否则主从不会超时
补充Case 3: 假如单个Binlog任务阻塞了45s,主从是否还能正常工作
能正常工作,不过主会建立slaveNode后超时,所以会报几条WANING:这里是任务A执行了45s时的情况
另外:
A 如果任务A执行了大于45S的时间,情况也是一样的(从这边因为resp阻塞处理,处于WaitReply时不检查超时,不会再发出TrySync,主那边因为SlaveNode已经删除了,就更没有什么超时检查了)
B 如果A执行时间在20S-40S之间,任务A的Ack也会被丢弃,因为SessionID对不上

当某个任务超时很久,如何避免运维不断告警:
给Master_Status_link加一个值域:connecting(原来只有up和down), 这样当Slave处于WaitReply或者WaitDBSync时,让Master_status_link处于connecting
6 额外的关联: 二次TrySync的问题在线上也出现过
线上不断Timeout的那台实例,其日志也符合上述问题的特征, 推测线上那个问题实例也是同一问题(该问题在单DB下也可能存在):
具体日志:
1 线上那台问题实例也出现了很相似的窗口Corruption:

2 线上的问题实例中,也会短时间内连续发出多个TrySync请求
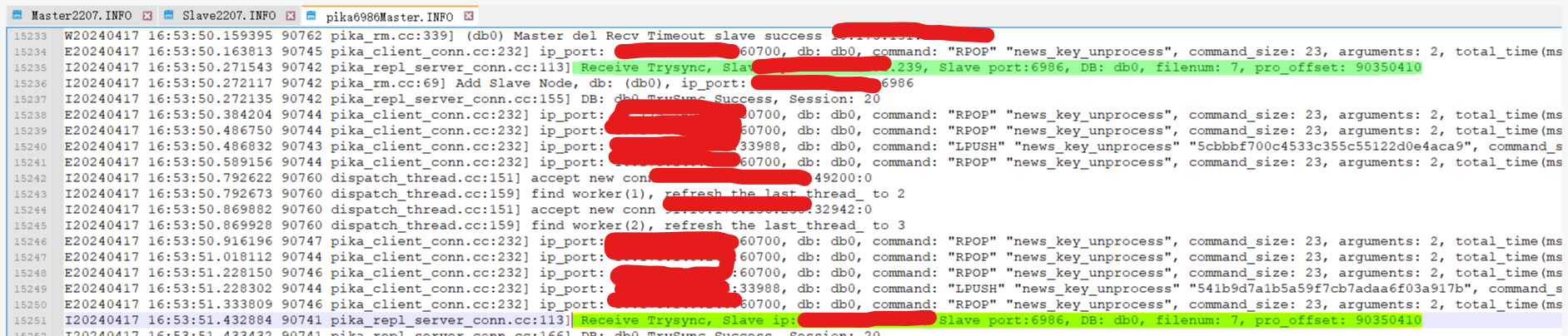
3 Slave端一样会出现这种CheckSessionID failed,而且sessionID极高,反映出主从之间不断在建连,次数有1000多,如果没有其他额外的问题,怀疑是因为每次建联时slave端都有积压的过期任务,进而导致slave再次转为TryConnect状态
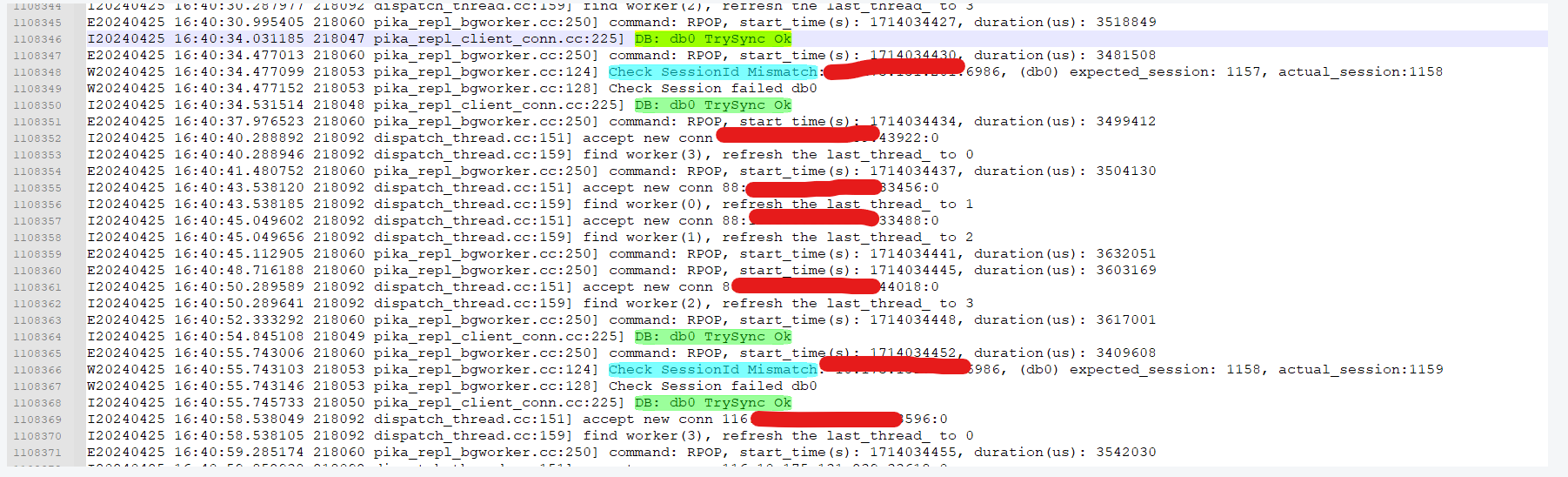
所以将前述的主从问题解决以后,该线上问题大概率也能一并消失。